This post is the third in a three-part series. The remaining two:
Part 3 is the last part in this short cycle. Here I’ll explain all the details around Time-based One-Time Password algorithm. I’ll finish up by also elaborating on things common to both, HMAC-Based One-Time Password algorithm:
- QR Codes used to easily transfer secrets from the server to the Authenticator app
- Base32 algorithm – used to store non-printable secret in a URI (effectively stored by the QR Codes mentioned above).
TOTP
One way to avoid the problems with lack of feedback between server and the app would be to shift from using a counter that is increasing with every authentication attempt to a counter based on, for example, a time stamp. This is what TOTP is actually doing.
Timestamp
TOTP works almost identically to HOTP. It’s calculating HMAC-SHA-1 using the key and a Big Endian representation of a counter, but the counter is based off of UNIX timestamp. And then is generating the code off of the resulting hash the same way as in HOTP.
UNIX timestamp is nothing more than a number of seconds that have elapsed since the midnight on Jan 1st, 1970 UTC. It’s a large unsigned integer that is being incremented by 1 every second.
We could design the algorithm to simply calculate the HMAC-SHA-1 directly from the key and that timestamp, but – since the timestamp changes every second – the code would change every second. 1 second to enter the code would not be enough, thus we have to make the timestamp change less often.
Having the timestamp increment by 1 every half a minute would make the code valid for 30 seconds, and, by doing that, the user would have up to 30 seconds to type in the code. This is exactly what TOTP is doing. The timestamp that TOTP is using is simply the UNIX timestamp divided by 30 and rounded down. That means that the 1st 30 seconds since midnight Jan 1st, 1970 UTC (00:00:00 – 00:00:29) the timestamp – equivalent of the counter in HOTP – was equal to 0. Next 30 seconds (00:00:30 – 00:00:59) it was equal to 1 and so on. You can check what is the current value of the timestamp right now using simple Python code:
>>> import time
>>> int(time.time()) // 30
54287637
>>>
Let’s take the above as an example. 54287637 in hex notation is 0x33c5d15. Just like in
HOTP we’re converting this to a Big-Endian-ordered array of 8 bytes:
index: 0 1 2 3 4 5 6 7
value: 00 00 00 00 03 3c 5d 15
And from this point on we proceed exactly as in HOTP, the difference being we give the above array as input to HMAC-SHA-1, instead of Big-endian-ordered table with the counter.
A bit of code
First off, if you want to validate the Python code below works properly, add new key to your Authenticator app (e.g. Google Authenticator):

and compare the results.
I will explain the details around the QR Codes later in this article. But for now, suffice
it to say, the code above contains our super-secret key: $3cr3tP4$$. The full text the
QR Code above resolves to:
otpauth://totp/your%40email.address?secret=EQZWG4RTORIDIJBE&issuer=TOTP%20Sample%20App
Just as the reminder, the value of secret argument above is a Base32 encoded key. In other words
$3cr3tP4$$ encoded in Base32 is EQZWG4RTORIDIJBE. You can double-check that by googling out
an online Base32 encoding/decoding tool and trying out yourself. And also later in this article
I’ll get into more details on Base32. I’ll also walk through encoding and decoding our password.
Another important thing is that if you want the Python code below to yield the correct codes, you must make sure your system’s clock is set correctly! The easiest way on Linux is to use NTP. That’s what I’m using.
Alright, let’s get to the actual Python code:
#! /usr/bin/env python3
import hmac
import time
key = "$3cr3tP4$$"
key_bytes = bytearray(key, "utf-8")
unix_timestamp = int(time.time())
timestamp = unix_timestamp // 30
# In TOTP code sample we're using actual system time, thus
# PLEASE, MAKE SURE YOUR SYSTEM TIME IS ACCURATE IF YOU WANT
# TO VALIDATE THE ACCURACY OF THE GENERATED CODES!
print(f"The UNIX timestamp's value right now is: {unix_timestamp}")
print(f"And the timestamp we'll use to generate the code: {timestamp}")
# Alright, the timestamp above is the equivalent of the counter
# from HOTP. From this point on we treat it exactly as we would
# treat the counter in HOTP. That means, we're converting it to
# an array of 8 Big-Endian-ordered bytes that represent the
# integer value of the timestamp variable.
timestamp_big_endian = timestamp.to_bytes(8, "big")
# And calculate the hash. It'll keep changing every 30 seconds
h = hmac.new(key_bytes, timestamp_big_endian, "sha1")
hash_value = h.digest()
print(f"In TOTP we calculate the hash the same way: {h.hexdigest()}")
# Ok, no the code to do the above. First let's calculate the offset.
# Unlike my HOTP code example, here we're using actual system time
# so every time the hash -- and therefore the offset -- will likely
# be different.
offset = hash_value[len(hash_value) - 1] & 0x0f
# Now let's get the code integer (we zero-out the most significant
# bit but only in the 1st -- the most significant -- byte)
code = (hash_value[offset] & 0x7f) * 0x1000000
code += (hash_value[offset + 1]) * 0x10000
code += (hash_value[offset + 2]) * 0x100
code += (hash_value[offset + 3])
print("The code integer: 0x%x" % code)
print(f"The code integer in decimal notation: {code}")
# And now we take only last 6 digits just like in HOTP.
code = code % 1000000
print(f"The final TOTP code: {code}")
Sample output of the script:
The UNIX timestamp's value right now is: 1628693586
And the timestamp we'll use to generate the code: 54289786
In TOTP we calculate the hash the same way: c09933121038ecf63e6fe5c5146d3e46272202c5
The code integer: 0x38ecf63e
The code integer in decimal notation: 955053630
The final TOTP code: 53630
QR Code
You can use any of the available QR Code scanners to scan the following code:

You’ll see that it decodes to the following text string:
otpauth://totp/patryk%40cisek.email?secret=56R2ORH6CZ2H75XVGN3AIVHLXRSOPFUG&issuer=TOTP%20Test%20Application
In that string are all the details needed for an app to start generating codes. It’s in a URI
(Uniform Resource Identifier)
format. For both, HOTP, and TOTP the scheme is always otpauth://. Next we have
authority, which is always either hotp or totp. Path is the account info (e.g.
login/email address etc.). Next we have a couple of parameters. The most important one
is secret. It contains a Base32-encoded key. And issuer
contains an info about the account provider (e.g. GMail/GitHub etc.).
It’s important to note that the email and the value of issuer aren’t really
important. They’re just helpers for the Authenticator app so that it can add some
meaningful data to the GUI alongside the codes. Like for which of your online accounts
is the code being generated for. The app is free to use/disregard those as it pleases.
For example (digression here), together with my Librem 13 I got a USB key, LibremKey, capable of performing both, HOTP, and TOTP. This key is based off of Nitrokey Pro2. With the newest version of libnitrokey (3.6) you’d be able to use nitrokey-app to manage both, HOTP, and TOTP also on LibremKey. However, this app lacks the capability to scan QR Codes. You’d have to be able to know the key (e.g. fish it out from the QR Code yourself) if you wanted to add it to your USB key. Since there are a couple of reasons I really like NitroKeys:
- they’re Open-Hardware
- they’re running Open-Source firmwares
- Nitrokey’s based and sold from German, yet shipping here to Canada was really cheap
my wife and I decided to write a simple TOTP authenticator app for desktop, Nitrokey Authenticator, that’s capable of scanning QR Codes and works with Nitrokey Pro2. Will also work with LibremKey once you have libnitrokey 3.6.
Quick note: we didn’t make it in time to ship libnitrokey 3.6 in Bullseye, but it’ll land in testing shortly after Bullseye’s release. I also missed the boat on releasing Nitrokey Authenticator in Bullseye. It already is in Debian Testing, though.
Anyway, as I’ve said it’s up to the authenticator app to decide how it’s going to use the
metadata information from the code. For example, our Nitrokey Authenticator,
when adding new key by scanning the QR Code, is presenting a dialog window where you can
name your new TOTP key slot. We’re prefilling it with the value of the issuer argument
withing the URI, and we completely omit – at least right now – the account info (the
email address in the above URI):
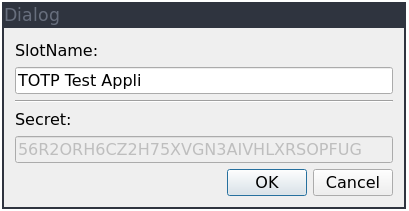
If you’re wondering why the Slot Name is truncated, that’s due to NitroKey’s hardware limitation of the slot name being not longer than 15 characters.
Now, as I’ve said, the most important part is the secret. You can see it in both, the URI
and – greyed-out – in the dialog window. This is the key that the app is passing
to HMAC-SHA-1 when generating codes!! You can see that the key is here comprised of only
printable ASCII characters. I’ve mentioned Base32 in the code section above, but let
me explain in more details here. Since both, HOTP, and TOTP are using URI to store
all the data, anything that is part of URI has to be one of URI-safe characters, which is
a small subset of the printable ASCII characters. Therefore, the binary key has to be
encoded somehow, so that it’s URI-safe. Because of that, HOTP, and TOTP both use
Base32.
Base32
Base32 is similar to much more popular Base64. The latter is used to encode binary data in a printable format, so that you can for example copy-paste it to your email, or on your website. Base64 is designed to use only printable characters because of that. Base32 is not only comprised of printable characters, but only of characters that can safely be put as part of and URI (e.g. any URL). The downside is the overhead of Base32 is even bigger than Base64. In other words, data encoded with Base32 will be longer than its Base64-encoded counterpart.
Base32 is using only upper-case letters: A-Z and digits: 2-7. Digits 0,1 are omitted
because of their similarity to O,I (capital o and capital i). This gives us 26
letters + 6 digits = 32 distinct characters – thus the name. Similarly, Base64 is using
64 distinct characters.
Anyway, in Base32 we use bi-directional mapping of integer values to/from the above sets of characters:
| 0 ⇋ A | 8 ⇋ I | 16 ⇋ Q | 24 ⇋ Y |
| 1 ⇋ B | 9 ⇋ J | 17 ⇋ R | 25 ⇋ Z |
| 2 ⇋ C | 10 ⇋ K | 18 ⇋ S | 26 ⇋ 2 |
| 3 ⇋ D | 11 ⇋ L | 19 ⇋ T | 27 ⇋ 3 |
| 4 ⇋ E | 12 ⇋ M | 20 ⇋ U | 28 ⇋ 4 |
| 5 ⇋ F | 13 ⇋ N | 21 ⇋ V | 29 ⇋ 5 |
| 6 ⇋ G | 14 ⇋ O | 22 ⇋ W | 30 ⇋ 6 |
| 7 ⇋ H | 15 ⇋ P | 23 ⇋ X | 31 ⇋ 7 |
Encoding
Let’s walk thru encoding our password/key: $3cr3tP4$$ using Base32.
- The 1st thing you have to do is write the password down in binary notation. Each byte of the key as the binary representation.
- Then group the string of ones and zeros in the groups of 5.
- Next convert those binary 5-digit long numbers into decimal notation.
- Now use the mapping above to transform each number into one of the corresponding characters (upper-case letters/digits).
Let’s do it with our password:
$ 3 c r 3 t P 4 $ $
0x24 0x33 0x63 0x72 0x33 0x74 0x50 0x34 0x24 0x24
00100100 00110011 01100011 01110010 00110011 01110100 01010000 00110100 00100100 00100100
00100 10000 11001 10110 00110 11100 10001 10011 01110 10001 01000 00011 01000 01001 00001 00100
4 16 25 22 6 28 17 19 14 17 8 3 8 9 1 4
E Q Z W G 4 R T O R I D I J B E
And there you have it – the result, Base32 encoded string of our password, is EQZWG4RTORIDIJBE.
Decoding
You literally just reverse the process.
- Convert each letter into the corresponding number using the mapping.
- Write down each of those numbers in binary notation.
- Now, group the sequence of ones and zeros in the groups of 8.
- Now, having those grouped in bytes, just reach those binary numbers to 1-byte long integers.
Let’s do that with our encoded password, EQZWG4RTORIDIJBE:
E Q Z W G 4 R T O R I D I J B E
4 16 25 22 6 28 17 19 14 17 8 3 8 9 1 4
00100 10000 11001 10110 00110 11100 10001 10011 01110 10001 01000 00011 01000 01001 00001 00100
00100100 00110011 01100011 01110010 00110011 01110100 01010000 00110100 00100100 00100100
0x24 0x33 0x63 0x72 0x33 0x74 0x50 0x34 0x24 0x24
------------------------------------------------------------------
at this point you're normally done. But, since our key is an ASCII
password, why not translating each of the above values into theirs
ASCII representations.
------------------------------------------------------------------
$ 3 c r 3 t P 4 $ $
And we got back from Base32-encoded string (EQZWG4RTORIDIJBE) to the password
($3cr3tP4$$).
Any leftovers
Our password happens to be 10 bytes long. That’s 80 bits. Now, 80 bits is exactly 16*5. We have exactly 16 5-bits long integers. No leftovers.
If our password was, for example, 2 bytes long – just for simplicity of explaining here
– we’d have 16 bits. That would be 3 full 5-bits long integers and we’d be left with
single (16th) bit. What should we do with that? Even though Base32 standard mentions
padding using 33rd character: =, TOTP apps are just ignoring leftovers. In particular,
when encoding, they’re just padding the string of ones and zeros with zeros to the nearest
full 5-bits long int, and using that to construct the last Base32 Character.
When decoding, you’d be left with some zeros that don’t add up to the full byte (less than
8 zeros) – you’d ignore them (cut them off), too.
Again, not to make this post too long, I’m not going to present any code for Base32 here.
But if you’d like to see a simple implementation of it, check out
our code
within Nitrokey Authenticator. In particular,
here
is where we’re filling up with 0 to fill-up to the full 5-bits long int when encoding. And
here
is where we’re cutting off leftover zeros, when decoding Base32.
Keep your QR Codes Private!!
From the above explanation you’ve probably already gathered – everything one would ever
need to generate the codes on your behalf would be to get their hands on the secret arg
of the QR Code! Even worse – they don’t even have to be technical. All they would
have to do is install Google Authenticator on their phone, run it and scan your QR Code.
They’re in.
Protect your QR Codes! Always!
Back ’em up!
If you lose access to your TOTP – maybe your phone got stolen, damaged, or otherwise rendered useless – then you have to recover somehow. Maybe the account, you’re using offers recovery codes. Maybe resetting password will be enough – it would likely reset password together with 2FA. But if none of those would be an option, you’d be cut off from your account.
Best take a screenshot of your QR Code and store it offline (e.g. on a flash drive).
Big fat warning about flash drives
Remember that when you write something to a flash drive, and don’t use it for months, the written data starts to wear off! You might end up with unreadable files! You’d be cut off all over again… Best approach is to, either, print them out, or remember about refreshing (rewriting) them on the flash drive. Or couple of flash drives. Or print them out AND keep refreshing them on couple of flash drives every couple of months.
The End
Hope that cycle of articles explains how simple and elegant both, HOTP, and TOTP algorithms are. Originally I planned 2 articles on that, but turned out, there was more to say about the topic than I originally thought.
I hope I was able to explain this in an easy and approachable fashion. If you have any feedback, don’t hesitate to email me.